

Patent databases may be a smoke screen that hides the true issues, problems, and dynamics of innovation behind the illusion that innovation is booming—and that patent activity measures the boom.
We are said to live in a time of remarkable innovation, with the computer/information revolution often compared to the Industrial Revolution in allowing people to produce more while working less. Economists, consultants, and other business gurus are striving mightily to quantify this revolution and to understand its sources and implications.
One popular metric is the number of new patents issued each year. For example, the pace of innovation might be gauged by the fact that there were 669,434 US patent applications and 390,499 new patents awarded in 2019, each triple the number in 1997. Lists of the most innovative companies, industries, and nations are often based on the number of patents, and patent analysis has now become a dominant method for studying innovation. The number of research papers in Google Scholar that contain the phrase “patent citation” rose from fewer than 10 in 1998 to more than 900 in 2014. Of the 20 papers published in the American Economic Review during the past decade on product, process, and service innovations, 9 used patent analyses. For Management Science, the leading management journal on innovation, it’s 11 of 15.
In addition to using patents to measure innovation, the citation of research papers in patent applications is used to gauge the effects of research on innovation. For example, a 2017 study published in Science, the world’s leading generalist science journal, looked at social science papers and concluded that “most patents (61 percent) link backward to a prior research article” and “most cited research articles (80 percent) link forward to a future patent.”
These efforts are commendable, but as discussed in one of the authors’ books, 9 Pitfalls of Data Science, the first pitfall is using bad data. It is far better to have a small amount of reliable and relevant data than a large amount of unreliable or irrelevant data. Patent data are a very “noisy” measure of innovation because most innovations are not patented and many patented inventions are not valuable. Matches are not patented, nor are three-point seat belts, computer mouses, and USB technology. Monoclonal antibodies are not patented, though they comprise six of the ten best-selling modern drugs. Since 1963, the journal Research and Development’s R&D 100 Awards have “identified and celebrated the top 100 revolutionary technologies of the past year.” A study by Roberto Fontana, Alessandro Nuvolari, Hiroshi Shimizu, and Andrea Vezzulli found that only 10 percent of the R&D 100 innovations were patented.
“Patent data are a very “noisy” measure of innovation because most innovations are not patented and many patented inventions are not valuable.”
On the other hand, patents have been awarded for thousands of seemingly useless inventions like bird diapers, a beer keg hat, and an “animal toy” that can be made of wood or wood composites and looks very much like a stick that might be thrown for a dog to fetch. There are also prophetic patents that are granted for things that don’t exist and may never exist, like Amazon’s patents for a flying warehouse, underwater warehouse, delivery blimp, and underground delivery tunnels.
Nor are patents closely related to profitability—past, present, or future. Of the top ten corporate patent applicants, only three were in the top 100 for market capitalization in 2019: IBM (9), Samsung (19), and Toyota (27). Of the top 10 companies in market capitalization, only four were among the top 100 patent applicants: IBM (8), GE (31), Microsoft (45), and Google (65). Apple, Exxon Mobil, PetroChina, Walmart, and Nestle are not in the top 100 for patent applications even though they are in industries that apply for many patents.
Patent law offers patent recipients protection in return for disclosure, but not all innovators benefit from this trade-off. Tesla CEO Elon Musk has said that, “We have essentially no patents in SpaceX. Our primary long-term competition is in China. If we published patents, it would be farcical, because the Chinese would just use them as a recipe book.”
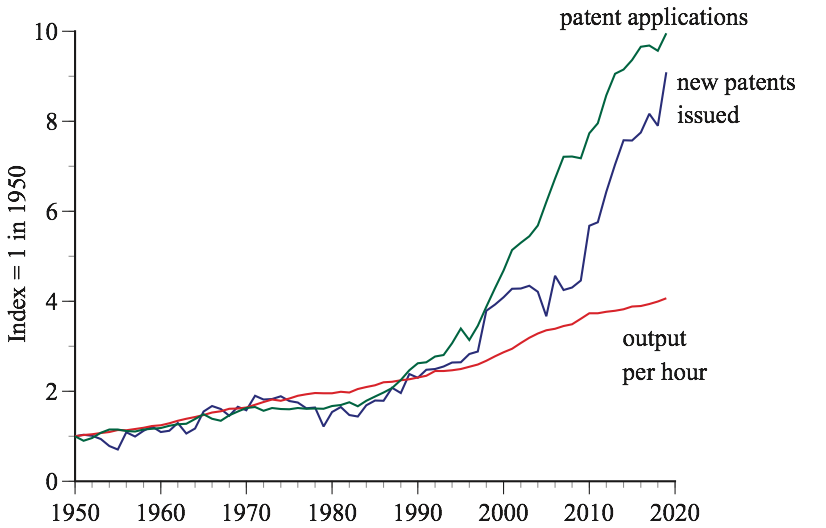
The key to a nation’s long-run economic growth is the effect of innovation on productivity; however, economists have long known that there is little correlation between productivity and patent activity. The figure shows the patent inflation that began in the US around 1990 as patents applications and awards soared while productivity languished. After increasing by nearly 3 percent a year between 1870 and 1970, US productivity growth slowed to 1.5 percent a year, then 1 percent, and is now about 0.5 percent. Even though patent activity paints a rosy picture of innovation, corporate revenue generated per dollar of corporate R&D spending has fallen by 65 percent since the 1970s.
To the extent that patent applications and infringement litigation are an expensive distraction for engineers, scientists, and managers, they might actually be a drag on productivity. The direct cost of a patent application is about $10,000; the total cost of the time spent by engineers, lawyers, and other personnel could easily push the total expense past $50,000. If so, the total cost of the 669,434 patent applications filed in 2019 was more than $30 billion, which is approximately half of the entire federal investment in nondefense R&D.
Some highly cited patents are extremely important and valuable, and some scientific papers are very influential, but the obsession with patent data suggests that such cases are everywhere, and are what drives an innovative economy, when in fact “home runs” like transistors are rare. Patent citation research is also self-serving in that it enables university professors to boast that they are writing papers that are cited in patents and it enables Science magazine and other journals to claim that they are the drivers of innovation and productivity growth.
The citation of research papers in patent applications is, in fact, a poor measure of knowledge flows. For instance, patent advisers and patent examiners often add papers to patent applications that the engineers and scientists who did the work may not have read, or even been aware of. The informal interactions between and among university and corporate scientists are often crucial for innovation, but difficult to document.
Patent databases may be a smoke screen that hides the true issues, problems, and dynamics of innovation behind the illusion that innovation is booming, and that patent activity measures the boom. More generally, the emphasis on patents and papers reflects a research obsession with large databases, sophisticated statistics, and elegant mathematics, which is the classic problem of looking for one’s lost keys under a streetlight. In this case, if the keys are the complex dynamics of science, innovation, and productivity, the streetlight is patent data, and what keeps researchers looking in the same wrong place is the academic incentive system, where publications are the sources of promotions, job security, social and intellectual status, and pay increases.
“The emphasis on patents and papers reflects a research obsession with large databases, sophisticated statistics, and elegant mathematics, which is the classic problem of looking for one’s lost keys under a streetlight.”
If patent analysis is a smoke screen, how should scholars study innovation? A starting point is the construction of databases that measure the actual value of science-based technologies such as superconductors, quantum computers, nanotechnology, synthetic food, glycomics, and tissue engineering; new forms of digital products such as augmented reality and drones; and new forms of internet services including those that are free, such as music and user-generated content.
Innovation studies could then focus on the origin of these new products, services, and processes. Did they come from existing technologies or new technologies? What enabled them to emerge when they did? Was it changes in regulation, demand, or costs, or were there advances in science that were applied naturally to new or existing products?
Researchers could also look at the extent to which the scientific research that has been funded over the past 20 to 40 years by the National Science Foundation, the National Institutes of Health, and other government agencies has led to new products, services, and processes (not the academic-paper counts that are currently favored, despite criticisms).
Linking advances in science with real products and services requires detailed case studies of the intermediate linkages and knowledge flows—the type of real-world, case-based studies that were pioneered decades ago by innovation scholars such as Kenneth Flamm on computers, Nathan Rosenberg and David Mowery on aircraft, Yujior Hiyami and Vernon Ruttan on agriculture, and Richard Nelson on transistors. We need more of this and fewer studies based on flawed patent data that gloss over the details and leave us with a vague feeling that innovation is occurring, that science supports this innovation, and that, as long as we have more of both, everything will be okay.
An understanding of the reasons for the productivity slowdown and how it can be reversed will require more than spreadsheets and p-values. Just as Charles Darwin left home to understand the real world, innovation scholars need to get their hands dirty, leaving the security of easily downloaded data in order to form meaningful insights.